BERT는 사실 Diffusion 모델이였다?!

BERT는 사실 Diffusion 모델이였다?!

최근 굉장히 흥미로운 글을 읽게되어 공유합니다.
원문 : link
BERT와 Diffusion이 같은 방식이다?!

NLP 연구자들에게 BERT는 너무 익숙한 모델입니다. 2018년 등장 이후, 수많은 자연어처리의 분류, 검색, QA 태스크에 활용됐습니다. [MASK] 토큰으로 단어를 가리고 맞추는 Masked Language Modeling(MLM)은 너무나 단순하고 명확한 학습 방식인데 강력한 성능으로 당시 많은 연구자들을 좌절케하기도 했었습니다.
Computer Vision(CV) 연구자들에게 Diffusion은 마찬가지로 익숙한 모델입니다. DALL-E, Stable Diffusion, Midjourney, … 등 이미지 생성의 표준이 된 이 기술은 노이즈를 점진적으로 추가했다 제거하는 방식으로 학습하여 이미지 생성 AI의 부흥을 이끌었습니다.
이 두 기술은 전혀 다른 분야, 전혀 다른 목적을 가진 다른 기술처럼 보였습니다.
그런데 문득 생각해보면, BERT의 MLM과 Diffusion의 노이즈를 추가했다가 제거하는 방식은 상당히 닮아있습니다.
Diffusion 기술을 텍스트에 적용한다고 하면, BERT의 MLM과 굉장히 유사한 방식이라는 걸 알 수 있습니다.
BERT의 MLM
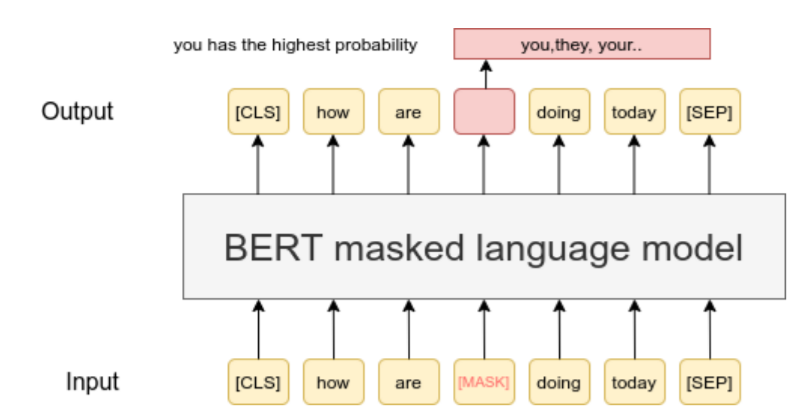
- 입력 텍스트의 15%를
[MASK]토큰으로 가림 - 마스킹된 토큰 예측
Diffusion
- 입력 이미지에 노이즈(
[MASK])로 가리고, 원복하는 방식 - 노이즈의 비율을 랜덤하게 적용한 방식으로 학습
즉, BERT는 Diffusion 방식을 딱 입력의 15%로만 고정해놓고 학습시킨 케이스라고도 볼 수 있는거 아니냐는겁니다.
그렇다면 BERT로 텍스트 생성도 가능한걸까?
그렇다면, Diffusion 모델이 생성 모델인것처럼, BERT 같은 인코더 모델을 Diffusion처럼 [MASK]의 비율을 높여서 학습한다면, GPT처럼 텍스트 생성이 가능한걸까요?
가능하다면, 굉장히 흥미로운 발견일겁니다. 최근 생성 AI는 GPT 같은 디코더 기반 모델이 주류를 이루고 있는데, 어쩌면 또다른 대안이 될테니까요.
심지어 아키텍처 변경이나 새로운 학습 알고리즘도 필요없이, 학습시 마스킹 비율만 랜덤하게 해주면 됩니다!
RoBERTa로 텍스트 생성해보기
원문 글의 저자인 Nathan Barry는 BERT의 강화된 버전인 RoBERTa 모델로 텍스트 생성 모델로 바꿔보는 실험을 진행했습니다.
핵심 아이디어는 위에서 설명한것처럼,학습할때 마스킹 비율을 랜덤하게 적용함으로써, 기존 BERT의 MLM을 발전시킨 방식으로 학습한다는 겁니다. (아래 코드는 Nathan이 적용한 diffusion_collator 예시입니다.)
def diffusion_collator(examples):
batch = tokenizer.pad(examples, return_tensors="pt")
# 기존 BERT: mask_prob = 0.15 (고정)
# Diffusion BERT: 매 배치마다 랜덤 선택
mask_prob = random.choice([1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1])
# 첫 16토큰은 프롬프트로 유지 (조건부 생성을 위해)
maskable_positions = batch.input_ids[:, PREFIX_LEN:]
mask = torch.rand(maskable_positions.shape) < mask_prob
batch.input_ids[:, PREFIX_LEN:][mask] = tokenizer.mask_token_id
return batch이제 학습 후, 텍스트를 생성할때는 앞에 프롬프트를 고정한 상태에서, [MASK]를 점차 채워나가는 방식으로 진행됩니다.
# 초기 상태: [프롬프트] + 240개의 [MASK]
mask_schedule = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0]
for step, mask_prob in enumerate(mask_schedule):
# 현재 마스킹된 위치 예측
outputs = model(input_ids=input_ids)
predictions = outputs.logits
# Top-k/top-p 샘플링으로 토큰 선택
for pos in masked_positions:
sampled_token = sample_from_logits(predictions[pos])
input_ids[pos] = sampled_token
# 다음 단계를 위해 일부 다시 마스킹
if mask_prob > 0:
remask_randomly(input_ids, mask_prob)- 단계별 생성 과정:
Step 0: [PROMPT] [MASK] [MASK] [MASK] [MASK] [MASK] ... (100% masked)
Step 1: [PROMPT] will [MASK] over [MASK] control ... (90% masked)
Step 2: [PROMPT] will begin [MASK] greater control ... (80% masked)
Step 5: [PROMPT] will begin to [MASK] greater control ... (50% masked)
...
Step 10: [PROMPT] will begin to assert greater control ... (0% masked - 완료)이러한 컨셉을 가지고 Nathan이 직접 학습해본 결과, H200으로 30분만의 학습으로,
Input Prompt:
Following their victory in the French and Indian War, Britain began to assert greater...Generated Text:
...dominion over Europe beginning about the early 19th. There conflict took
place on the island, between British and Irish Ireland. British officials
administered British Ireland, a Celtic empire under the control of the Irish
nationalist authorities, defined as a dominion of Britain. As the newly Fortic
states acquired independent and powerful status, many former English colonies
played their part in this new, British @-@ controlled colonial system...와 같은 결과를 보이게 됐습니다..!
놀랍게도 문법적으로 올바르면서도 그럴듯한 문장을 생성해냈습니다. 겨우 30분의 추가 학습만으로요.
이 개념의 시사점
- NLP와 CV 커뮤니티가 서로 다르게 발전시켜온 기술이 사실 비슷한 방식이라는 점
- 기존 BERT 계열의 모델들(BERT, RoBERTa, ELECTRA, DeBERTa, …)이 잠재적 생성 모델이였다는 것
- 양방향성 : GPT는 태생적으로 단방향(left to right) 모델인데, BERT는 양방향 문맥을 고려하는 모델입니다. 이러한 태생적인 차이가 생성쪽에 어떻게 활용될 수 있을지도 고민해볼만한 포인트입니다
물론 BERT 같은 인코더 모델이 상용에 적용될만한 모델이 되려면 기존 GPT처럼 여러 엔지니어링적인 고민들이 필요할것입니다. 하지만 AI 연구자들에게는 GPT 아키텍처만이 아닌 새로운 선택지가 생겼다는 것만으로도 굉장히 흥미로운 사실입니다 :)
Reference
Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox