Sooftware NLP - DeepSpeed Usage

DeepSpeed Usage
최근 인공지능 모델은 사이즈가 점점 커지는 추세입니다.
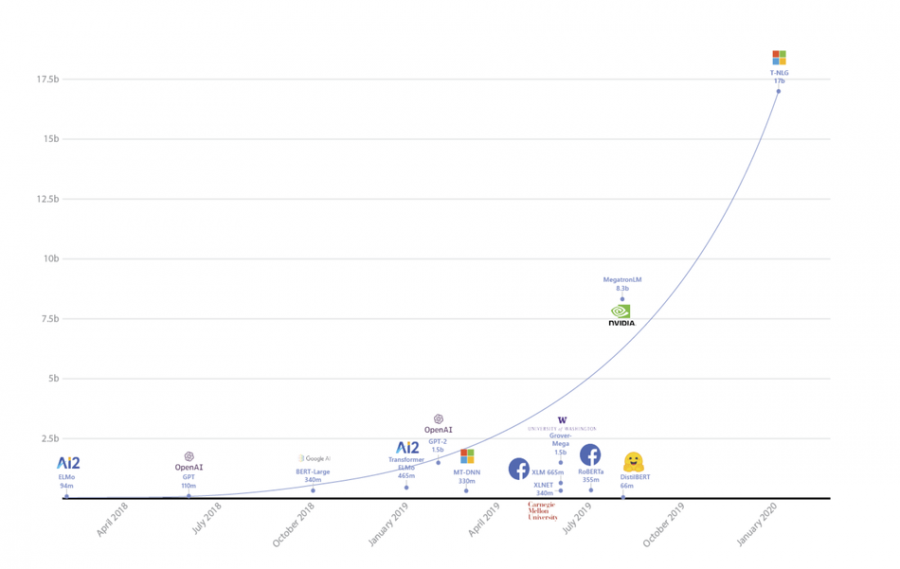
다른 어떤 방법보다도 그냥 더 큰 모델, 더 많은 데이터를 집어넣으면 더 좋은 모델이 만들어지는게 현실인 것 같습니다. 문제는 큰 모델은 학습시키기가 어렵다는 건데요, 많이 쓰이는 비싼 GPU A100이 메모리 40GB인데, 2B 넘어가는 모델은 학습시에 GPU 1대에 올릴수가 없어서 Model Parallelism과 같은 방법으로 모델을 쪼개서 GPU에 올리거나 해야합니다.
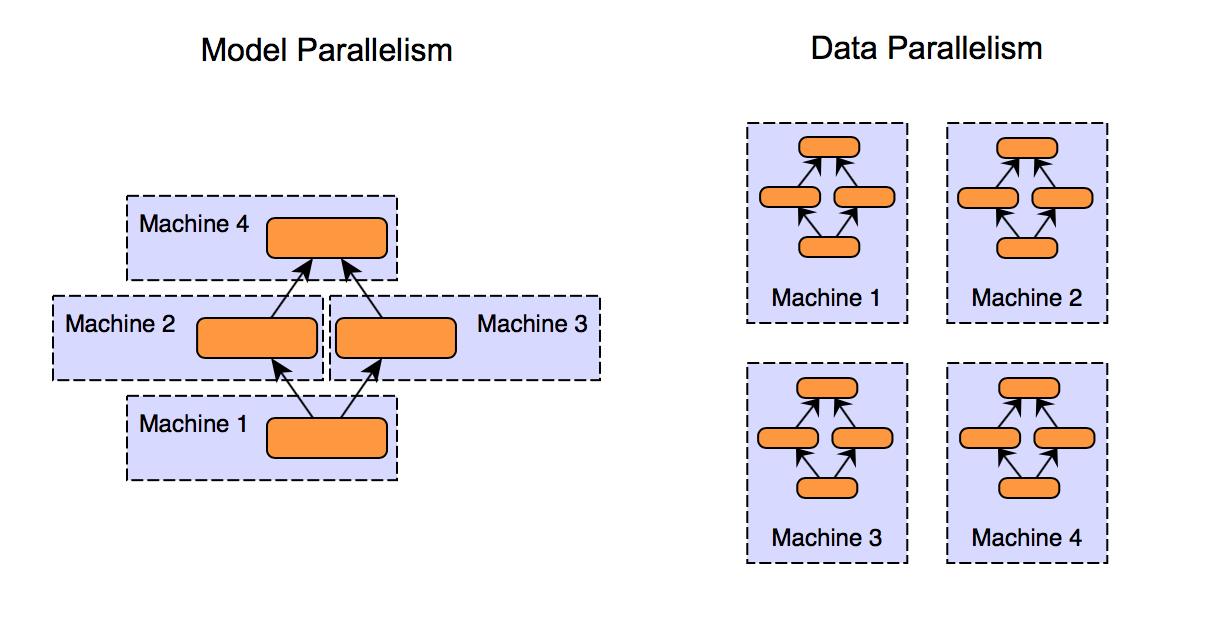
근데 이런 Model Parallelism을 직접 하나하나 구현하려면 굉장히 어렵습니다. 하지만 고맙게도 Microsoft에서 DeepSpeed라는 오픈소스를 공개해주었습니다.
DeepSpeed는 지나치게 큰 모델에 대한 트레이닝에 어려움을 겪는 개발자들을 위해 기존보다 10배 이상 큰 모델을 5배 이상의 속도로 게다가 코드 변화 거의 없이 학습 시킬 수 있는 혁명적인 오픈소스 라이브러리입니다.
이번 포스트에서는 DeepSpeed 사용법에 대해 간단하게 기록해둘까 합니다.
예제 코드는 2.7B의 파라미터를 가진 GPT-Neo 2.7B 모델로 테스트 했습니다.
Dataset 클래스 정의 등의 디테일한거는 스킵했습니다.
기존 PyTorch Code
import torch
from torch.utils.data import DataLoader
from transformers import GPTNeoForCausalLM, AutoTokenizer, LineByLineDataset
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = AutoTokenizer.from_pretrained('EleutherAI/gpt-neo-2.7B')
model = GPTNeoForCausalLM.from_pretrained('EleutherAI/gpt-neo-2.7B')
dataset = LineByLineDataset(...)
data_loader = DataLoader(dataset=dataset,
num_workers=args.num_workers,
batch_size=args.batch_size,
drop_last=False)
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer=optimizer,
max_lr=args.lr,
epochs=args.num_epochs,
steps_per_epoch=len(data_loader),
anneal_strategy='linear')
for step, batch in enumerate(data_loader):
input_ids, attention_masks, labels = batch
input_ids = input_ids.to(device)
attention_masks = attention_masks.to(device)
labels = labels.to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_masks, labels=labels)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.gradient_clip_val)
optimizer.step()
scheduler.step()DeepSpeed Code
import torch
import deepspeed
from torch.utils.data import DataLoader
from transformers import GPTNeoForCausalLM, AutoTokenizer, LineByLineDataset
torch.distributed.init_process_group(backend="nccl")
deepspeed.init_distributed("nccl")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = AutoTokenizer.from_pretrained('EleutherAI/gpt-neo-2.7B')
model = GPTNeoForCausalLM.from_pretrained('EleutherAI/gpt-neo-2.7B')
config = {
"train_batch_size": 1,
"fp16": {
"enabled": True,
},
"zero_optimization": {
"stage": 2,
"contiguous_gradients": True,
"overlap_comm": True,
"offload_optimizer": {
"device": "cpu",
"pin_memory": True,
"fast_init": True
},
},
"optimizer": {
"type": "Adam",
"params": {
"lr": 3e-05,
"betas": [
0.9,
0.999
],
"eps": 1e-8
}
},
}
dataset = LineByLineDataset(...)
data_loader = DataLoader(dataset=dataset,
num_workers=args.num_workers,
batch_size=args.batch_size,
drop_last=False)
model, optimizer, _, _ = deepspeed.initialize(model=model,
config_params=config,
model_parameters=model.parameters())
for step, batch in enumerate(data_loader):
input_ids, attention_masks, labels = batch
input_ids = input_ids.to(device)
attention_masks = attention_masks.to(device)
labels = labels.to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_masks, labels=labels)
loss = outputs.loss
model.backward(loss)
model.step()기존 코드에서 큰 변화 없이 몇 가지 사항만 수정해주면 deepspeed 적용이 가능합니다.
Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox