Sooftware NLP - Electra Paper Review

Below is just about everything you’ll need to style in the theme. Check the source code to see the many embedded elements within paragraphs.
ELECTRA
Abstract
- BERT에서 제안한 Masked Language Modeling(MLM)은 좋은 성능을 보여줬지만, 전체 데이터의 15%만을 마스킹해서 학습 효율 측면에서 좋지 않음.
- ELECTRA는 모델의 성능과 함께 학습의 효율성도 개선할 수 있는 방법을 제안함.
- Replaced Token Detection(RTD)라는 새로운 pre-training 태스크 제안.
- ELECTRA의 장점은 Small 모델에서 두드러짐. 1개의 GPU로 4일만 학습한 모델로 계산량이 30배인 GPT를 능가.
Replaced Token Detection (RTD)
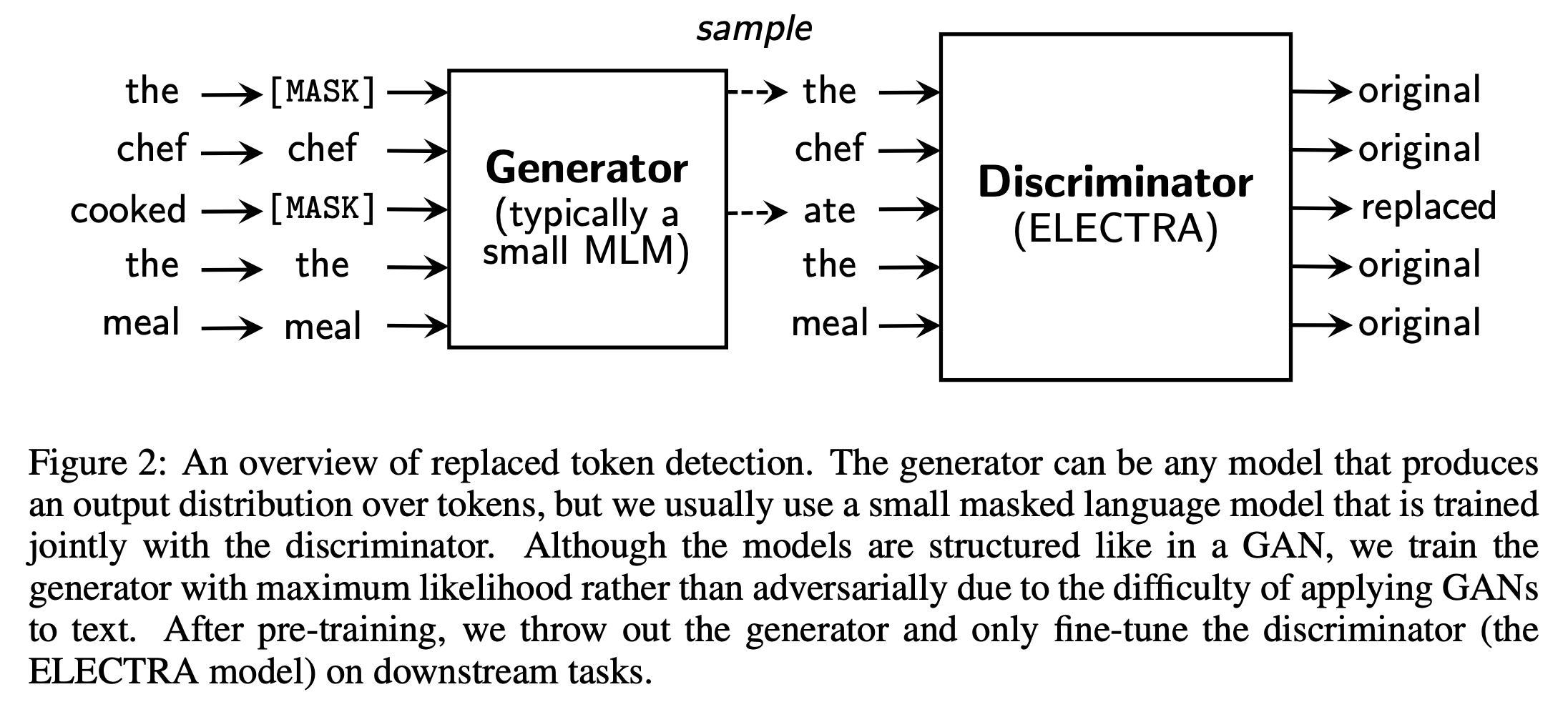
- Generator: BERT의 MLM
- 입력된 인풋 중 15%의 토큰을 [MASK]로 가림
- [MASK]로 가려진 인풋의 원래 토큰을 예측
- Discriminator
- 입력 토큰 시퀀스에 대해서 각 토큰이 original인지 replaced인지 이진 분류로 학습
- 학습 과정
- Generator에서 마스킹 된 입력 토큰들을 예측
- 마스킹할 위치의 토큰에 대해 generator가 예측했던 softmax 분포에서 높은 순위의 토큰 중 하나로 치환 (1위: cooked, 2위: ate, 3위: … 이였으면 MLM은 cooked를 선택하지만 해당 과정에서 ate를 가져오는 방식)
- Original input : [the, chef, cooked, the, meal]
- Input for generator : [[MASK], chef, [MASK], the, meal]
- Input for discriminator : [the, chef, ate, the, meal]
- 치환된 입력에 대해 discriminator는 원래 입력과 동일한지 치환된 것인지를 이진 분류로 예측
Training Algorithm
- Jointly 학습
- Generator와 Discriminator를 동시에 학습시키는 방법
- Two-stage 학습
- Generator만 MLM으로 N 스텝동안 학습
- 뒤이어 해당 모델을 Discriminator로 N 스텝동안 학습시키는 방식 (이때 Generator의 웨이트는 고정)
- Adversarial 학습
- Adversarial training을 모사해서 학습시키는 방식 (jointly보다 좋지 않아서 자세히 안 봤습니다.)
Result
Performance & Efficiency
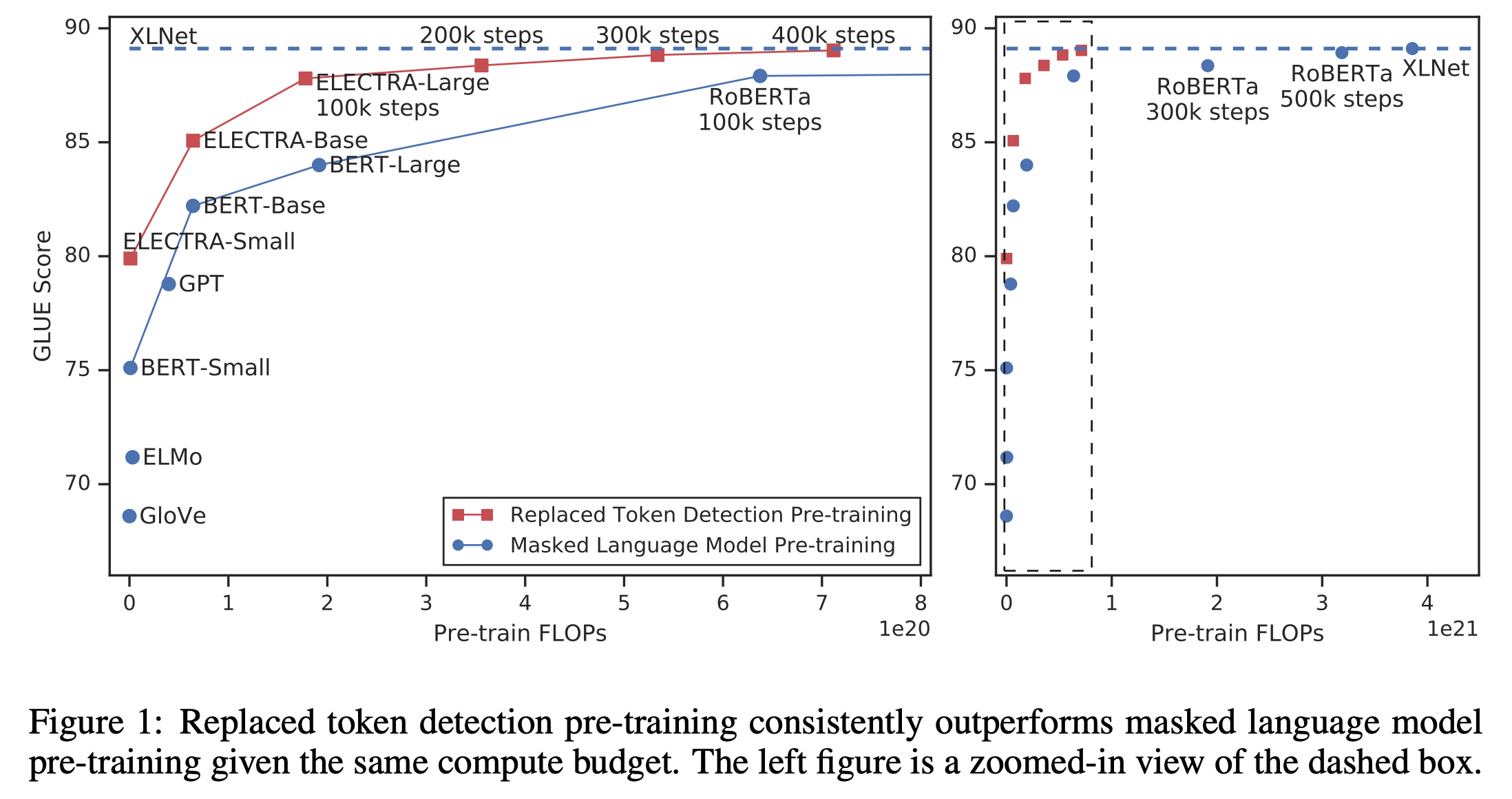
- 다른 모델들에 비해 매우 빠르게 성능이 향상되는 것을 볼 수 있음
- 그럼에도 불구하고, 기존 BERT보다 더 좋은 성느을 기록함.
Weight Sharing
- Generator와 discriminator는 모두 트랜스포머의 인코더 구조.
- 그렇기 때문에 3가지 선택사항이 생김.
- Generator, Discriminator가 서로 독립적으로 학습 (83.5)
- 임베딩 레이어의 웨이트만 공유 (84.3)
- 모든 레이어의 웨이트를 공유 (84.4)
- 결과적으로 모든 웨이트를 공유하는 것이 가장 좋은 성능을 보임.
Training Algorithm
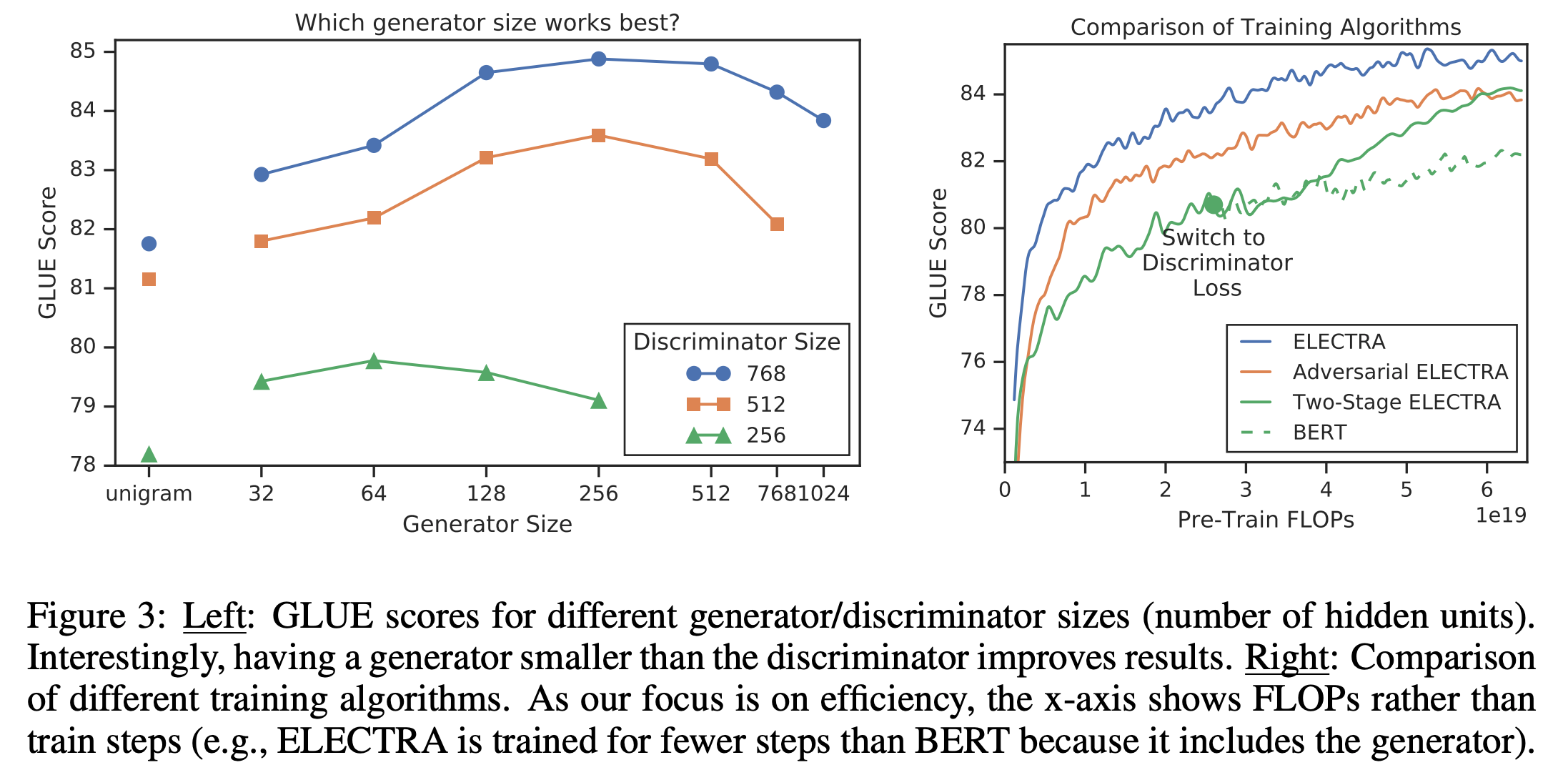
- Jointly 방식이 가장 성능이 좋았음 (왼쪽은 discriminator와 generator의 사이즈에 따른 실험)
Conclusion
- 더 효율적이고 효과도 좋은 Replaced Token Detection (RTD) 제안
- 메인 아이디어는 Generator가 만들어 낸 질 좋은 negative sample로 학습함으로써 더 적은 리소스로 모델을 더욱 견고하게 만드는 것.
Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox