Sooftware Speech - 한국어 Tacotron2

한국어 Tacotron2
이번 포스팅에서는 Tacotron2 아키텍처로 한국어 TTS 시스템을 만드는 방법에 대해 다루겠습니다.
Tacotron2
Tacotron2는 17년 12월 구글이 NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS 논문에서 제안한 Text-To-Speech 모델입니다.
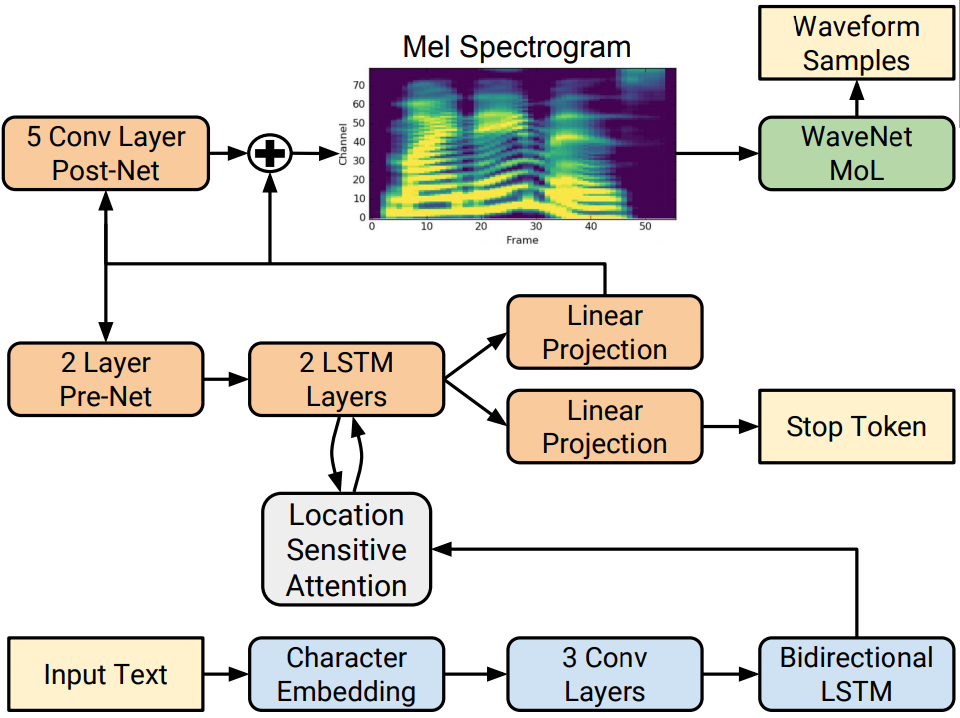
Text-To-Speech 아키텍처는 크게 텍스트에서 Mel-Spectrogram을 생성하는 Mel-Network와 Mel-Spectrogram에서 Audio Signal을 생성하는 Vocoder로 이루어져 있습니다. Tacotron2는 Mel-Network에 해당하는 구조입니다.
이 Tacotron2 논문에서 이미 Mel-Network는 성능이 상당히 좋아졌기 때문에 이후 연구들은 주로 Vocoder를 개선하거나 이 Tacotron2 구조를 개선해서 Multilingual, Cross-lingual, Multi-Speaker를 적용하는 연구가 많이 나왔습니다.
지금까지도 대부분의 연구에 Tacotron2가 베이스가 된 만큼 자연어처리에 트랜스포머가 있다면 TTS에는 Tacotron2가 있다고 보면 될 것 같습니다.
NVIDIA Tacotron2
TTS의 어려운 점은 입문하기 위해서는 신호처리 개념이 많이 필요하다는 것입니다. 음성인식 같은 태스크도 어느 정도의 신호처리 개념이 필요하지만, TTS 시스템은 조금 더 신호처리 쪽에 예민하기 때문에 더 많은 지식이 요구됩니다.
음성인식 시스템의 경우 librosa 라이브러리에서 MFCC 혹은 Mel-Spectrogram과 같은 피쳐를 뽑아서 그냥 바로 사용해도
성능에 크게 문제가 있지는 않습니다만, TTS 시스템은 조금 더 정교하게 피쳐를 뽑아줄 필요가 있습니다.
저도 처음에 Tacotron2를 구현해본다고 그냥 librosa 라이브러리에서 Mel-Spectrogram을 뽑아서 학습했다가 모델 성능이
좋지 않았던 경험이 있습니다.
하지만 다행히도, NVIDIA에서 Tacotron2 를 아주 잘 구현해서 오픈소스로 공개했습니다. NVIDIA 구현체의 경우 apex 등을 이용해서 학습 최적화를 잘 해놔서 학습 속도도 빠르다는 장점이 있어서 현재는 많은 연구들에서도 Tacotron2를 쓰는 경우는 거의 NVIDIA 구현체를 사용하고 있을 정도로 표준이 됐습니다.
NVIDIA Tacotron2 Data Format
NVIDIA Tacotron2는 아래와 같은 데이터셋 포맷을 필요로 합니다.
- train_filelist.txt
/data/tts_datas/000001.wav|튜닙은 자연어처리 테크 스타트업입니다
/data/tts_datas/000002.wav|타코트론은 대표적인 음성합성 모델이에요
/data/tts_datas/000003.wav|음성합성 기술 어렵지 않아요
...
...오디오는 22050Hz의 샘플링 레이트를 가지는 오디오가 필요하며, 위 예시처럼 오디오 경로와 해당하는 텍스트를 |로 구분한 형태의 txt 파일이 필요합니다.
NVIDIA Tacotron2 for Korean
NVIDIA Tacotron2 구현체는 대표적인 TTS 데이터셋인 LJ Speech 데이터를 예제로 제공합니다.
LJ Speech 데이터셋은 영어 데이터셋이기 때문에 한국어 데이터셋인 KSS 과 같은 데이터셋을 사용하기 위해서는 약간의 수정이 필요합니다.
영어든 한국어든 음성 처리는 똑같습니다만, 텍스트 처리를 수정해주어야 합니다. NVIDIA 구현체에서는 해당 소스코드가 text 폴더에 구현이 되어 있습니다.
여기서 우리가 구현해주어야 할건 text_to_sequence() 함수입니다. 해당 함수는 튜닙은 자연어처리 테크 스타트업입니다와 같은 텍스트를 입력으로 받아
토크나이징 및 숫자 표현으로 인코딩해주는 역할을 수행합니다.
def text_to_sequence(text: str):
...
...
print(text_to_sequence("튜닙은 자연어처리 테크 스타트업입니다"))
# [18, 38, 4, 41, 58, 13, 39, 45, 105, 14, 21, 13, 27, 45, 13, 25, 16, 25, 7, 41, 105, 18, 26, 17, 39, 105, 11, 39, 18, 21, 18, 39, 13, 25, 58, 13, 41, 58, 4, 41, 5, 21, 1]text_to_sequence() 함수는 크게 3가지 기능을 수행하면 됩니다.
-
텍스트 클리닝
-
토크나이징
-
숫자 표현으로 인코
텍스트 클리닝
먼저 TTS 인풋으로 어떤 문자열이 들어올지 모르므로, 허용 가능한 문자들만 들어오도록 제한해야 합니다.
## 그까이꺼~ 그냥~ 대애애충! 하면 되지 $^$@]][ 않나...?
=> 그까이꺼 그냥 대애애충! 하면 되지 않나?그리고 한국어 TTS 구현시, 단위를 문자 단위가 아닌 자소(자음, 모음) 단위로 해주어야 성능이 더 좋다고 합니다.
즉 국이란 문자가 있으면 이거를 ㄱㅜㄱ으로 쪼개어 주어야 합니다. 그리고 여기서 중요한 점은 국의 처음에 나온 ㄱ과
끝에 나온 ㄱ이 서로 다르다는 점입니다. 우리 눈에는 똑같은 ㄱ이지만, 컴퓨터 내에서는 초성과 종성을 다르게 처리할 수 있습니다.
한국어 TTS 시스템에서는 이렇게 초성과 종성을 서로 다르게 표현해주어야 합니다. 다음 예제처럼 unicodedata 라이브러리를 사용하면 쉽게 적용 가능합니다.
- Normalize X
text = "타코트론"
for t in text:
print(t, end=" ")
# 타 코 트 론- NFKD Normalize
import unicodedata
text = "타코트론"
text = unicodedata.normalize('NFKD', text)
for t in text:
print(t, end=" ")
# ㅌ ㅏ ㅋ ㅗ ㅌ ㅡ ㄹ ㅗ ㄴ 이렇게 NFKD 방식으로 문자열을 분해해주게 되면 초성, 중성, 종성을 분리할 수 있습니다.
참고: 이렇게 분리한 텍스트는 NFKC 방식으로 다시 문자 형태로 합칠 수 있습니다.
아래는 제가 구현한 텍스트 클리닝 함수입니다.
import re
import unicodedata
def normalize(text):
text = unicodedata.normalize('NFKD', text)
text = text.upper()
text = text.replace('%', unicodedata.normalize('NFKD', '퍼센트'))
regex = unicodedata.normalize('NFKD', r"[^ \u11A8-\u11FF\u1100-\u115E\u1161-\u11A70-9A-Z?!]")
text = re.sub(regex, '', text)
text = re.sub(' +', ' ', text)
text = text.strip()
return text토크나이징 & 인코딩
텍스트 클리닝을 했으면, 이제 토크나이징 및 인코딩을 수행해야 합니다.
이미 앞의 텍스트 클리닝 과정에서 NFKD로 텍스트를 분해해놨기 때문에, 텍스트를 for문만 돌리면 쉽게 토크나이징이 가능합니다.
하지만 토크나이징을 하면서 동시에 숫자 형태로 인코딩을 수행해주기 위해서는 Vocabulary를 먼저 정의해야합니다. Vocabulary는 모델에 입력될 수 있는 모든 텍스트를 숫자와 1:1 매핑을 시켜주는 dictionary 형태로 생각해주시면 됩니다.
저는 한국어 TTS 시스템에 사용할 Vocabulary를 다음과 같이 구성했습니다.
- 스페셜 토큰: _, ~ (pad, eos)
- 초성: 0x1100 ~ 0x1113
- 중성: 0x1161 ~ 0x1176
- 종성: 0x11A8 ~ 0x11C3
- 알파벳: ABCDEFGHIJKLMNOPQRSTUVWXYZ
- 숫자: 0123456789
- 특수문자: ?! (띄어쓰기 포함)
해당 Vocabulary를 구성하는 코드는 아래와 같습니다.
CHOSUNGS = "".join([chr(_) for _ in range(0x1100, 0x1113)])
JOONGSUNGS = "".join([chr(_) for _ in range(0x1161, 0x1176)])
JONGSUNGS = "".join([chr(_) for _ in range(0x11A8, 0x11C3)])
ALPHABETS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
NUMBERS = "0123456789"
SPECIALS = " ?!"
ALL_VOCABS = "".join([
CHOSUNGS,
JOONGSUNGS,
JONGSUNGS,
ALPHABETS,
NUMBERS,
SPECIALS
])
VOCAB_DICT = {
"_": 0,
"~": 1,
}
for idx, v in enumerate(ALL_VOCABS):
VOCAB_DICT[v] = idx + 2그리고 이렇게 정의한 VOCAB_DICT를 이용해서 아래와 같이 tokenize 함수를 구현할 수 있습니다.
def tokenize(text, encoding: bool = True):
tokens = list()
for t in text:
if encoding:
tokens.append(VOCAB_DICT[t])
else:
tokens.append(t)
if encoding:
tokens.append(VOCAB_DICT['~'])
else:
tokens.append('~')
return tokens전체 구현은 아래와 같습니다.
text/__init__.py
import re
import unicodedata
CHOSUNGS = "".join([chr(_) for _ in range(0x1100, 0x1113)])
JOONGSUNGS = "".join([chr(_) for _ in range(0x1161, 0x1176)])
JONGSUNGS = "".join([chr(_) for _ in range(0x11A8, 0x11C3)])
ALPHABETS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
NUMBERS = "0123456789"
SPECIALS = " ?!"
ALL_VOCABS = "".join([
CHOSUNGS,
JOONGSUNGS,
JONGSUNGS,
ALPHABETS,
NUMBERS,
SPECIALS
])
VOCAB_DICT = {
"_": 0,
"~": 1,
}
for idx, v in enumerate(ALL_VOCABS):
VOCAB_DICT[v] = idx + 2
def normalize(text):
text = unicodedata.normalize('NFKD', text)
text = text.upper()
text = text.replace('%', unicodedata.normalize('NFKD', '퍼센트'))
regex = unicodedata.normalize('NFKD', r"[^ \u11A8-\u11FF\u1100-\u115E\u1161-\u11A70-9A-Z?!]")
text = re.sub(regex, '', text)
text = re.sub(' +', ' ', text)
text = text.strip()
return text
def tokenize(text, encoding: bool = True):
tokens = list()
for t in text:
if encoding:
tokens.append(VOCAB_DICT[t])
else:
tokens.append(t)
if encoding:
tokens.append(VOCAB_DICT['~'])
else:
tokens.append('~')
return tokens
def text_to_sequence(text):
text = normalize(text)
print(text)
tokens = tokenize(text, encoding=True)
return tokens이렇게 새로 구현한 함수들을 사용하기 위해서는 hparams.py와 data_utils.py를 몇 군데 수정해주어야 하는데,
필요한 수정을 다 적용한 코드는 https://github.com/sooftware/nvidia-tacotron2 을 사용하시면 됩니다.
Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox