Sooftware NLP - Longformer Paper Review

Longformer: The Long-Document Transformer
Introduction
- 트랜스포머는 긴 시퀀스는 처리하지 못한다는 한계를 가지고 있음
- 이유는 시퀀스 길이에 O(n^2)하게 늘어나는 높은 복잡도 때문
- 본 논문은 Attention 이루어지는 복잡도를 낮추는 방법을 제안 (O(n))
- BERT는 512 토큰을 limit으로 가지는데, 본 논문 모델은 4096 토큰까지 가능
text8,enwik8,Wiki-Hop,TriviaQA에서 State-Of-The-Art 달성
Attention Method
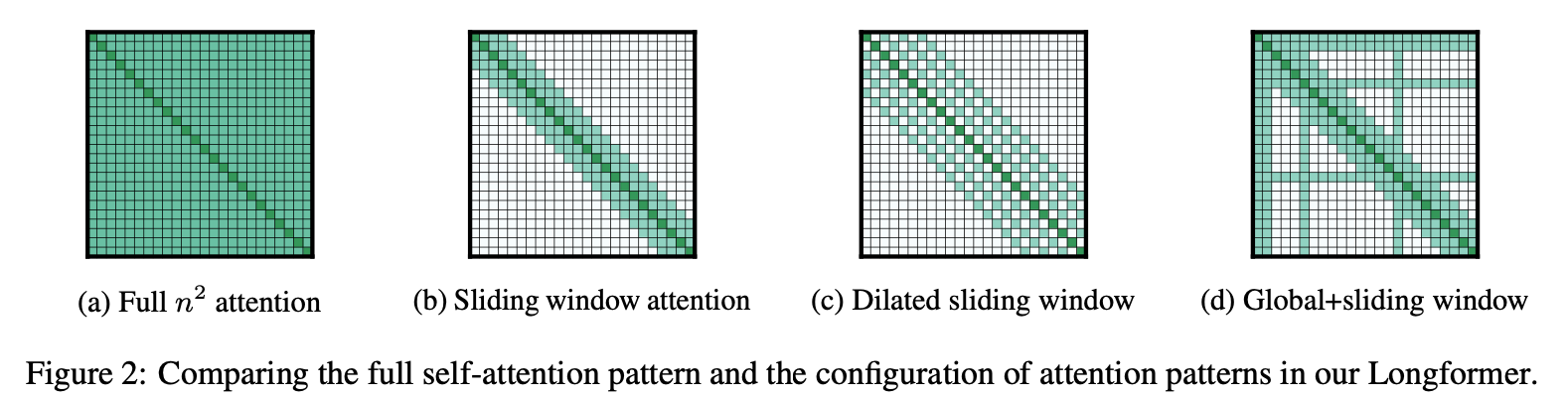
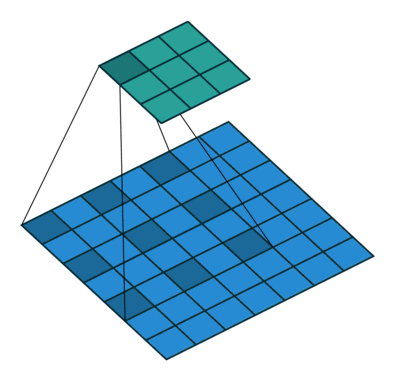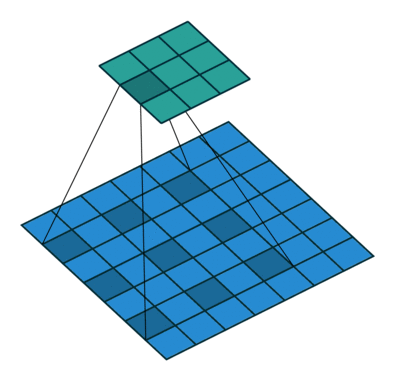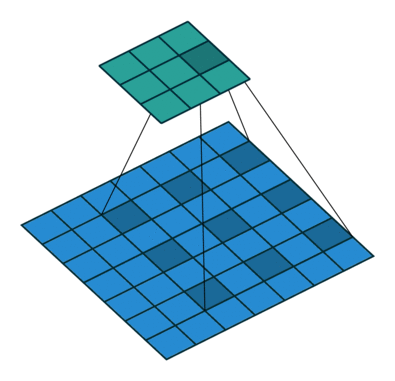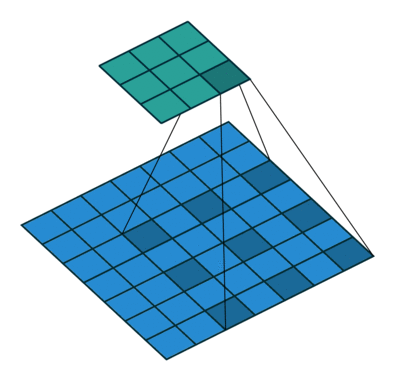
본 논문에서는 위 그림과 같은 3가지 어텐션 방식을 제안
Sliding window Attention
- 크기가 w인 sliding window 내에서만 attention을 수행하는 방법
- 이 방법은 텍스트 길이 n에 대해 O(n x w)의 복잡도를 가짐
- 이러한 방식은 레이어가 깊어짐에 따라 receptive field가 넓어지는 CNN과 유사함
- 예) window size가 2일 때, 레이어가 쌓일수록 w만큼 receptive field가 넓어짐.
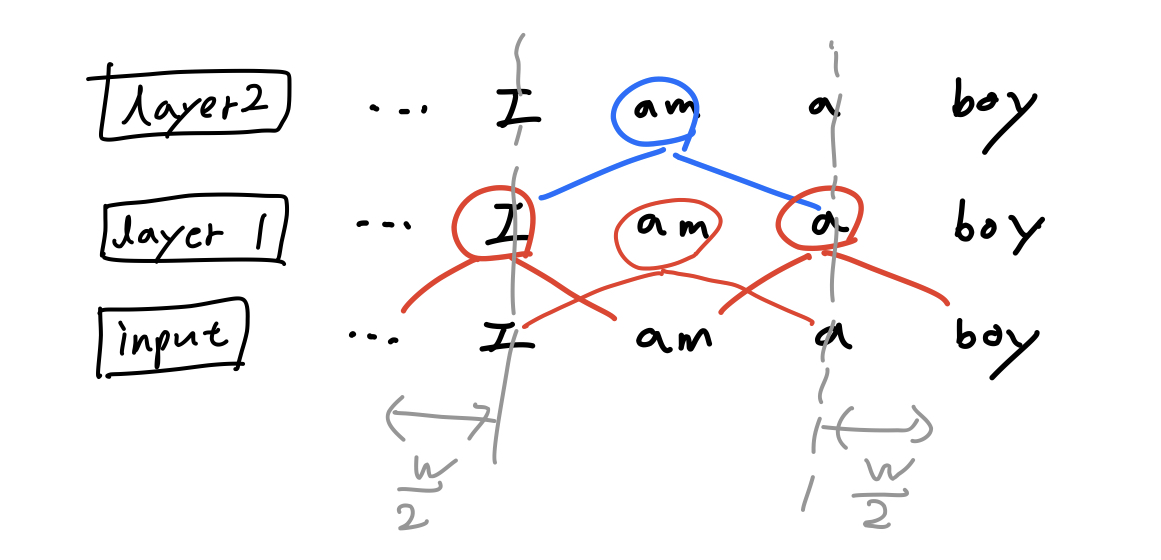
- l x w의 receptive field size를 가지게 됨.
- 각 레이어마다 w의 크기를 다르게 주는 방법이 도움이 될 수도 있음
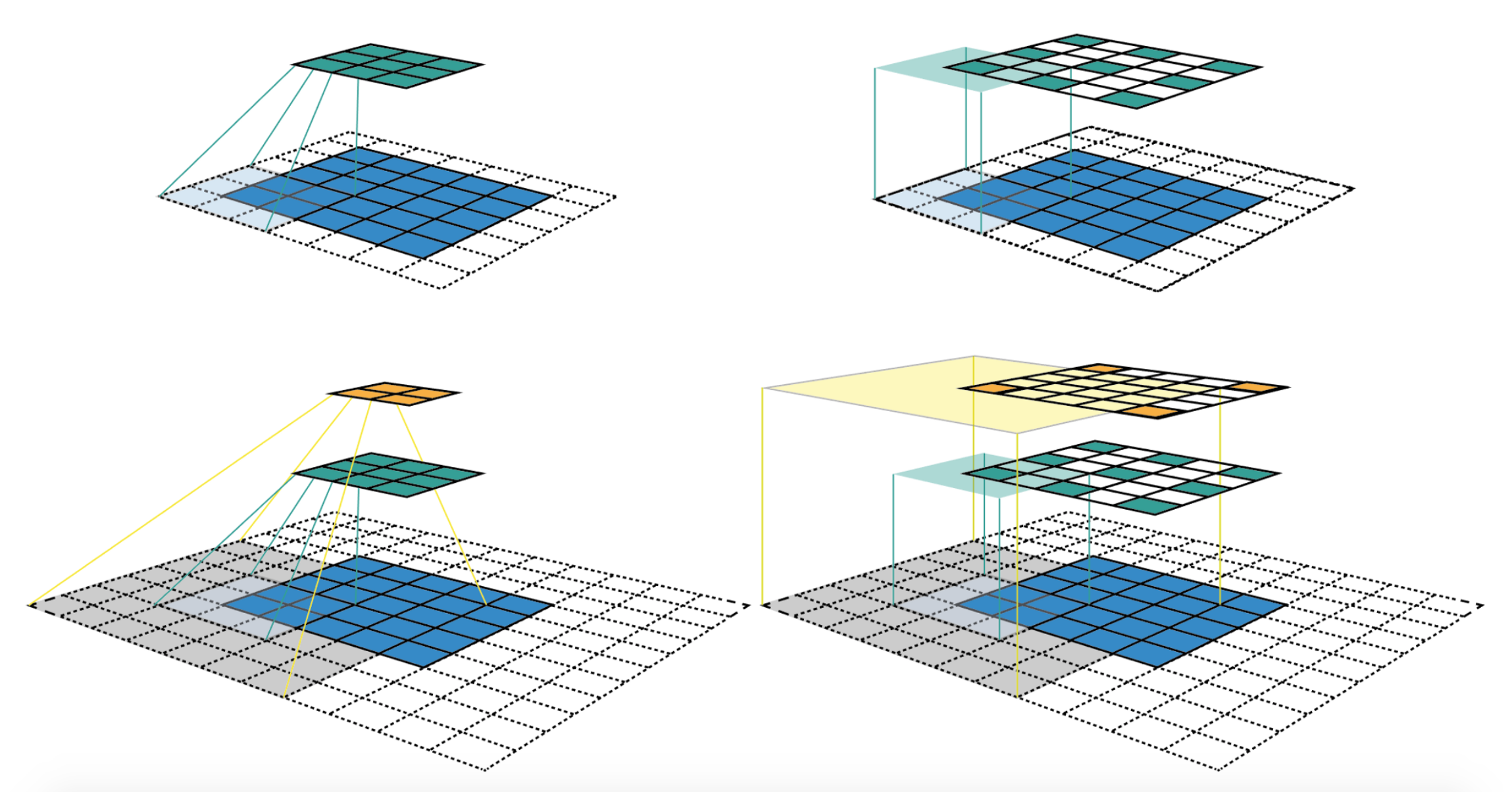
Dilated Sliding Window
- Sliding window attention보다도 receptive field를 더 넓히기 위해 고안된 방법
- Dilated Convolution에서 착안
- dilated 값을 줘서 토큰을 d만큼 건너뛰면서 어텐션하도록 하는 방법
- 예) window size가 2이고 dilation size가 2일 때, 아래 그림과 같이 w x d만큼 receptive field가 넓어짐
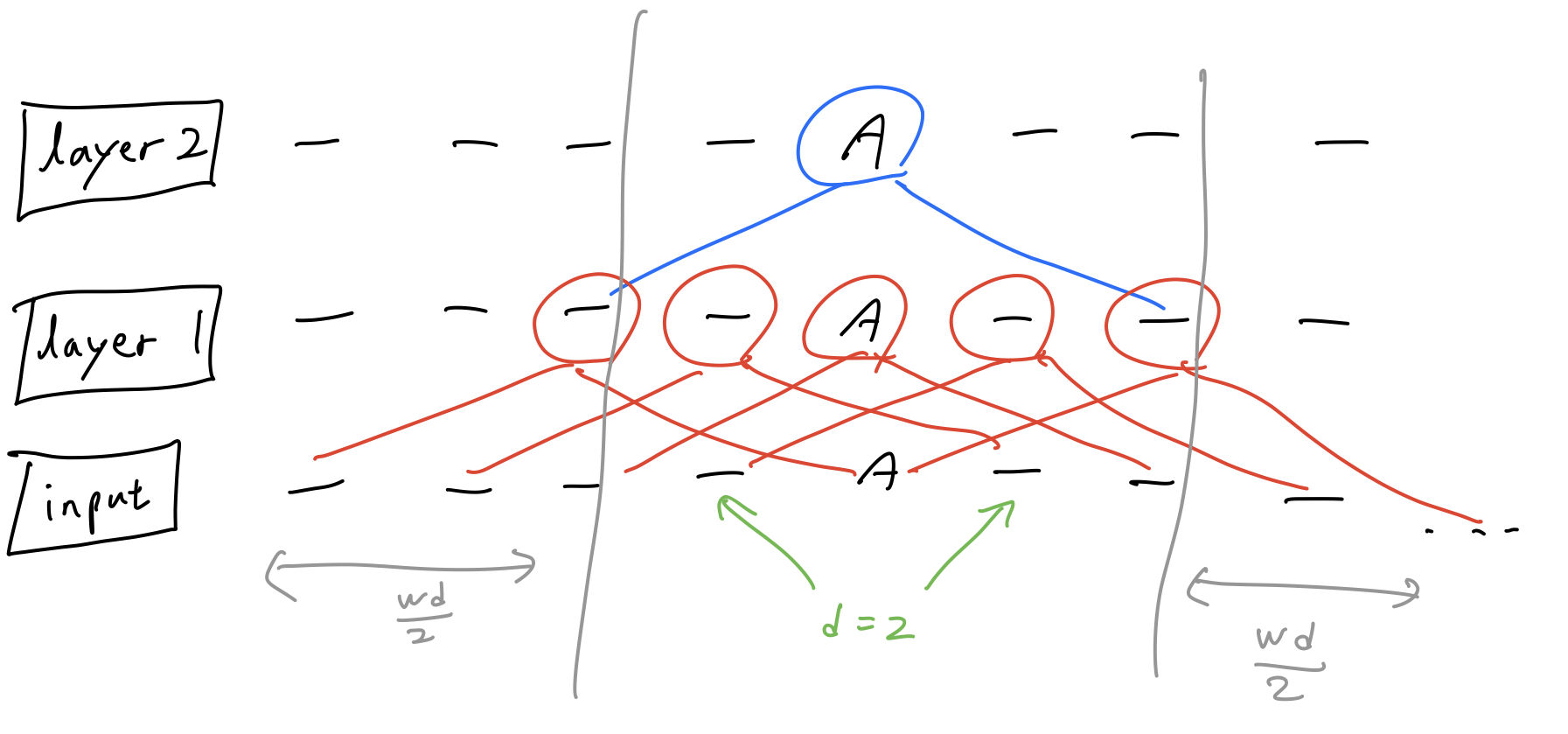
- l x d x w의 receptive field size를 가지게 됨.
Global Attention
- BERT의 [CLS] 토큰 같은 경우는 전체 컨텍스트를 바라봐야하는데, 위의 2가지 방법만으로는 Finetuning하는 태스크에서는 부족한 부분이 있을 수 있음
- 따라서 스페셜 토큰 몇 개에 대해서는 global attention을 수행하도록 함.
- 전체 토큰 수에 비해서는 스페셜 토큰은 매우 적기 때문에 복잡도는 여전히 O(n)
Linear Projections for Global Attention
- 보통의 트랜스포머의 어텐션은 Q, K, V로 이루어 지는데, sliding window 기반 어텐션과 global 어텐션을 위해 sliding Q, K, V와 global Q, K, V 두 세트로 나눠서 어텐션을 계산하도록 구현
Experiments
2가지 방식으로 평가를 진행.
Autoregressive Language Modeling
- 모델 자체의 임베딩 평가를 위함
- character/token 단위의 language modeling을 수행.
text8,enwik8데이터셋에서 SOTA를 달성- 본 태스크는 dilated sliding window attention 사용
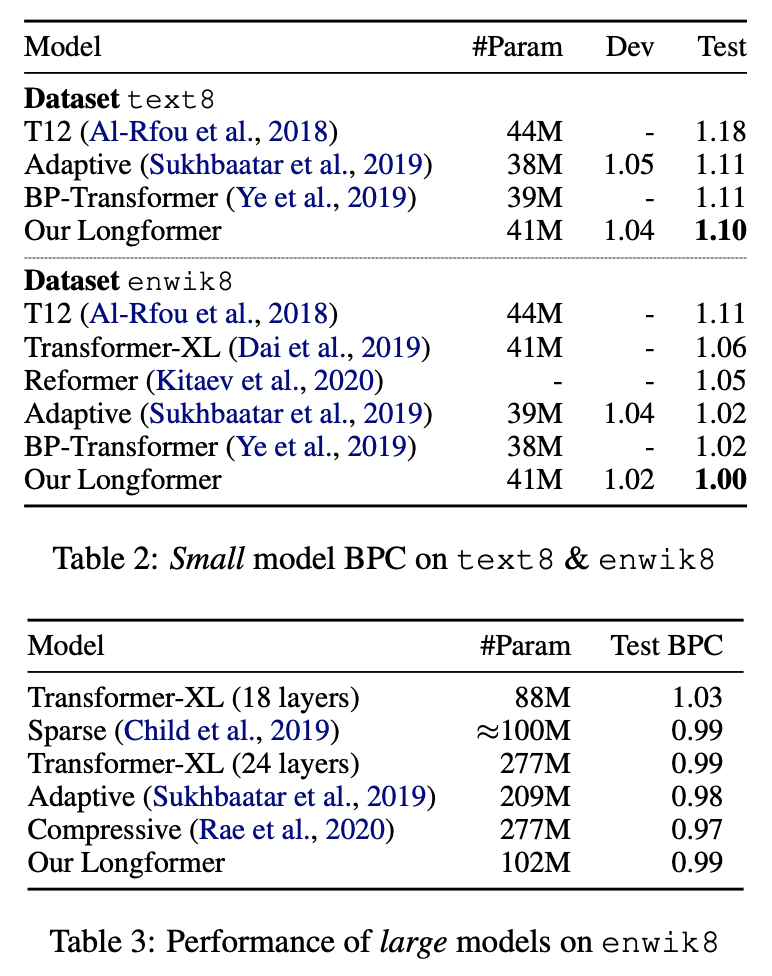
Pre-training and Fine-tuning
- RoBERTa 체크포인트로부터 시작해서 학습
- sliding window attention를 사용
- 각 태스크에 따라 스페셜 토큰을 지정하여 global attention을 사용
WikiHop과TriviaQA에서 SOTA 달성

Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox