Sooftware Speech - MFCC (Mel-Frequency Cepstral Coefficient)

MFCC (Mel-Frequency Cepstral Coefficient)
- ‘Voice Recognition Using MFCC Algorithm’ 논문 참고
MFCC란?
음성인식에서 MFCC, Mel-Spectrogram는 빼놓고 얘기할 수 없는 부분이다.
간단히 말하면, MFCC는 ‘음성데이터’를 ‘특징벡터’ (Feature) 화 해주는 알고리즘이다.

머신러닝에서 어떠한 데이터를 벡터화 한다는 것은 곧 학습이 가능하다는 의미이기 때문에 상당히 중요한 부분이라고 할 수 있다. 데이터에서 Feature를 어떤 방법으로 뽑느냐에 따라 모델의 성능이 상당히 좌우될 수 있기 때문에 굉장히 중요하다.
이러한 MFCC Feature는 파이썬에서는 제공되는 librosa라는 라이브러리를 이용해서 간단하게 뽑아올 수 있다.
import librosa
def get_librosa_mfcc(path, n_mfcc: int = 40):
SAMPLE_RATE = 16000
HOP_LENGTH = 128
N_FFT = 512
signal, sr = librosa.core.load(path, SAMPLE_RATE)
return librosa.feature.mfcc(signal, sr, hop_length=HOP_LENGTH, n_fft=N_FFT)위 코드는 음성데이터의 파일 경로를 넘겨받아 해당 음성데이터의 MFCC Feature를 뽑아주는 함수이다.
여기서 SAMPLE_RATE는 음성데이터의 형식에 따라 다를 수 있다.
( Ex MP4 : 44100, PCM, WAV 16000 etc.. )
밑으로는 MFCC Algorithm이 어떤 식으로 Feature를 뽑는지에 대해 수식 없이 직관적인 내용만으로 설명하겠다.
Mel-Scale
MFCC를 알기 위해서 먼저 Mel이 뭔지를 알아야 한다. Mel은 사람의 달팽이관을 모티브로 따온 값이라고 생각하면 된다! 기계에게 음성을 인식시키기 전에, 사람은 어떤 식으로 음성을 인식하는지를 살펴보자.
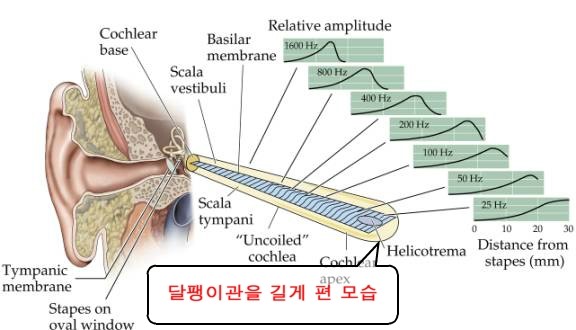
사람은 소리를 달팽이관을 통해 인식한다.
그럼 달팽이관은 어떤 식으로 소리를 인식할까??
달팽이관을 똘똘 말려있지만, 실제로 길게 펴서 보면 달팽이관의 각 부분은 각기 다른 진동수(주파수)를 감지한다.
이 달팽이관이 감지하는 진동수를 기반으로 하여 사람은 소리를 인식한다.
그렇기 때문에 이 주파수(Frequency)를 Feature로 쓰는 것은 어떻게 보면 당연한 얘기이다. 하지만, 달팽이관은 특수한 성질이 있다.
주파수가 낮은 대역에서는 주파수의 변화를 잘 감지하는데, 주파수가 높은 대역에서는 주파수의 변화를 잘 감지하지 못한다는 것이다.
예를 들어, 실제로 사람은 2000Hz에서 3000Hz로 변하는 소리는 기가막히게 감지하는데, 12000Hz에서 13000Hz로 변하는 소리는 잘 감지를 하지 못한다.
이 이유를 달팽이관의 구조로 살펴보면, 달팽이관에서 저주파 대역을 감지하는 부분은 굵지만 고주파 대역을 감지하는 부분으로 갈수록 얇아진다
그렇다면, 특징벡터로 그냥 주파수를 쓰기 보다는 이러한 달팽이관의 특성에 맞춰서 특징을 뽑아주는 것이 더욱 효과적인 피쳐를 뽑는 방법일 것이다.
그래서 위와 같이 사람 달팽이관 특성을 고려한 값을 Mel-scale이라고 한다.
Short-Time Fourier Transform
그리고 두 번째로 고려해야 할 사항이 있다. 음성데이터에서 주파수(frequency)를 성분을 뽑아내야 한다면 당연히 Fourier Transform을 해야 할 것이다. 그렇다면 음성데이터에 대해서 전체를 퓨리에 변환을 했다고 생각해보자.
사람이 발성하는 음성은 그 길이가 천차만별일 것이다. “안녕하세요”라고 하더라도, 어떤 사람은 1초, 어떤 사람은 3초가 걸릴 수도 있다. 그래서 음성 데이터에서 한 번에 Mel-Scale을 뽑게 되면, 이 천차만별인 길이에 대하여 같은 “안녕하세요”라는 음성이라고 학습시키기는 어려울 것이다.
위와 같은 문제를 해결하기 위해 음성데이터를 모두 20~40ms로 쪼갠다. 여기서 사람의 음성은 20~40ms 사이에서는 음소(현재 내고 있는 발음)가 바뀔 수 없다는 연구결과들을 기반으로 음소는 해당 시간내에 바뀔 수 없다고 가정한다.
그래서 MFCC에서는 음성데이터를 모두 20~40ms 단위로 쪼개고, 쪼갠 단위에 대해서 Mel 값을 뽑아서 Feature로 사용하는 것이다.
MFCC (Mel Frequency Cepstral Coefficient)
위에서까지 MFCC가 어떤 건지에 대해 대략적으로 이해했다면, 이제 MFCC 내부에서 어떤 식으로 동작하는지를 살펴보자.
다음은 MFCC 추출 과정을 잘 설명한 블록 다이어그램이다.
(출처 : ‘Voice Recognition Using MFCC Algorithm’ 논문)

위의 과정을 하나하나 직관적으로 살펴보자.
Pre-Emphasis
간단히 말하면 High-pass Filter이다. 사람이 발성 시 몸의 구조 때문에 실제로 낸 소리에서 고주파 성분은 많이 줄어들게 되서 나온다고 한다. (이게 본인이 생각하는 본인 목소리와 다른 사람이 생각하는 본인 목소리가 다른 이유라고 한다) 그래서 먼저 줄어든 고주파 성분을 변조가 강하게 걸리도록 High-pass Filter를 적용해주는 과정이다.
Sampling and Windowing
Pre-emphasis 된 신호에 대해서 앞에서 언급했던 이유 때문에 신호를 20~40ms 단위의 프레임으로 분할한다. 여기서 주의할 점은, 이 때 프레임을 50%겹치게 분할한다는 것이다. 프레임끼리 서로 뚝뚝 떨어지는 것이 아니라 프레임끼리 연속성을 만들어주기 위해 프레임을 50% 겹치게 분할한다. (물론 겹치는 정도는 조정가능한 파라미터이다)
여기서 왜 연속성이 필요한지 궁금할 수 있다. 만약 프레임이 서로 뚝뚝 떨어지게 샘플링을 한다면, 프레임과 프레임의 접합 부분에서 순간 변화율이 ∞ (무한대) 가 될 수 있다. 이러한 부분을 방지하기 위한 과정이다.

그리고 이 프레임들에 대해 Window를 각각 적용한다. 보통 Hamming Window를 많이 사용한다. 여기서 각각의 프레임들에 대해서 window를 적용하는 이유는, A frame과 B frame이 서로 연속되지 않는다면, 프레임이 접합하는 부분에서의 주파수 성분이 무한대가 되어버린다. 이러한 일을 방지하기 위해 프레임의 시작점과 끝점을 똑같이 유지해주기 위해서 Hamming Window를 적용한다.(Window 종류는 굉장히 다양한데, Hammin window가 Default라고 생각하면 된다)
Fast Fourier Transform
각각의 프레임들에 대하여 Fourier Transform을 통하여 주파수 성분을 얻어낸다. 여기 FFT 까지만 적용하더라도 충분히 학습 가능한 피쳐를 뽑을 수 있다. 하지만 사람 몸의 구조를 고려한 Mel-Scale을 적용한 feature가 보통 더 나은 성능을 보이기 때문에 아래의 과정을 진행한다.
Mel Filter Bank
가장 중요한 부분이다. 각각의 프레임에 대해 얻어낸 주파수들에 대해서 Mel 값을 얻어내기 위한 Filter를 적용한다. 아래의 그림으로 보면 쉽게 이해가 쉬울 듯 하다.

앞에서 언급했듯이, 달팽이관의 특성을 고려해서 낮은 주파수에서는 작은 삼각형 Filter를 가지고, 고주파 대역으로 갈수록 넓은 삼각형 Filter를 가진다고 생각하면 된다.

그래서 위와 같은 삼각형 필터 N개를 모두 적용한 필터를 Mel-filter Bank 라고 부른다. 하여, 퓨리에 변환을 통과한 신호를 위의 Mel-filter Bank를 통과하게 되면 Mel-Spectrogram이라는 피쳐가 뽑히게 된다. 최근에는 뒤의 과정을 거치지 않고 여기까지 구한 Mel-Spectrogram을 사용하는 경우가 많다.

Discrete Cosine Transform (DCT) 연산
앞에서 나온 Mel-Spectrogram이라는 피쳐에 대해 행렬을 압축해서 표현해주는 DCT 연산을 수행한다. 여기까지 해주면, Output으로 MFCC (Mel-Frequency Cepstral Coefficient)가 나오게 된다. 앞의 Mel-Spectrogram은 주파수끼리 Correlation이 형성되어 있는데, 이러한 상관관계를 De-Correlate해주는 역할 또한 수행한다. 위의 과정을 파이썬 NumPy를 이용해서 구현한 블로그가 있다. 코드를 하나하나 보면서 자세히 이해하고 싶은 분들은 아래의 링크를 추천한다.
https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox