Sooftware Speech - Conformer Paper Review

Conformer: Convolution-augmented Transformer for Speech Recognition
Anmol Gulati et al.
Google Inc.
INTERSPEECH, 2020
Reference
Summary
- Transformer 기반 모델이 음성인식 분야에서 좋은 성능을 보이고 있음
- Self-attention 기반한 트랜스포머는 global-context 정보를 잘 표현하지만, local-context에서는 부족하다는 단점이 있음
- 반면, CNN 기반 모델은 local-context는 잘 표현하지만 global-context를 반영하기 위해서는 적당한 dilation과 깊은 구조를 가져야 함
- 이 두 방법을 결합하여 global-context와 local-context 모두 잘 표현할 수 있도록 하기 위한 transformer + CNN 결합구조인 Conformer 구조 제안
- Conformer Encoder + Transducer 구조
Conformer Encoder
기존 트랜스포머 블록과 다르게 2개의 Feed Forward Network (FFN)에 쌓인 Sandwich 방식으로 구성
Conformer encoder model architecture

기존 트랜스포머 인코더 블록은 Multi Head Self Attention (MHSA) → LayerNorm → Feed Forward Network (FFN) → LayerNorm 구조에서 FFN Module → MHSA Module → Conv Module → FFN Module → LayerNorm 구조로 변경
Multi-Headed Self-Attention Module

- Relative positional encoding
절대적인 position 정보를 더하는 방식이 아닌, 상대적인 position 정보를 주는 방식 절대적인 position 정보가 a=1, b=2와 같이 값을 지정하고 그 값의 차이를 계산하는 방식이라면, 상대적인 position 정보는 a=1, b=2이든 a=5, b=6이든 상관없이 두 수(위치)의 차이가 1이라는 것만 알려주면 되는 방식
이런 방식은 가변적인 시퀀스 길이 인풋에 대해 인코더를 robust하게 만들어 줌
- Pre-norm
기존 트랜스포머는 Post-norm인데 반해, pre-norm 적용
이전 연구들에서 pre-norm은 깊은 모델 학습이 원활하게 되도록 도와주는 효과가 있다고 알려짐
Convolution Module

- Pointwise Conv

kernel size가 1x1로 고정된 convolution dimension을 맞출 때 자주 쓰임
- GLU Activation
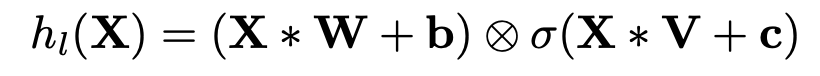

- Depthwise Conv
그룹이 채널수와 같은 Group-Convolution. 각 channel마다의 spatial feature를 추출하기 위해 고안된 방법
>>> nn.Conv(in_channels=10, out_channels=10, group=10)- Swish activation
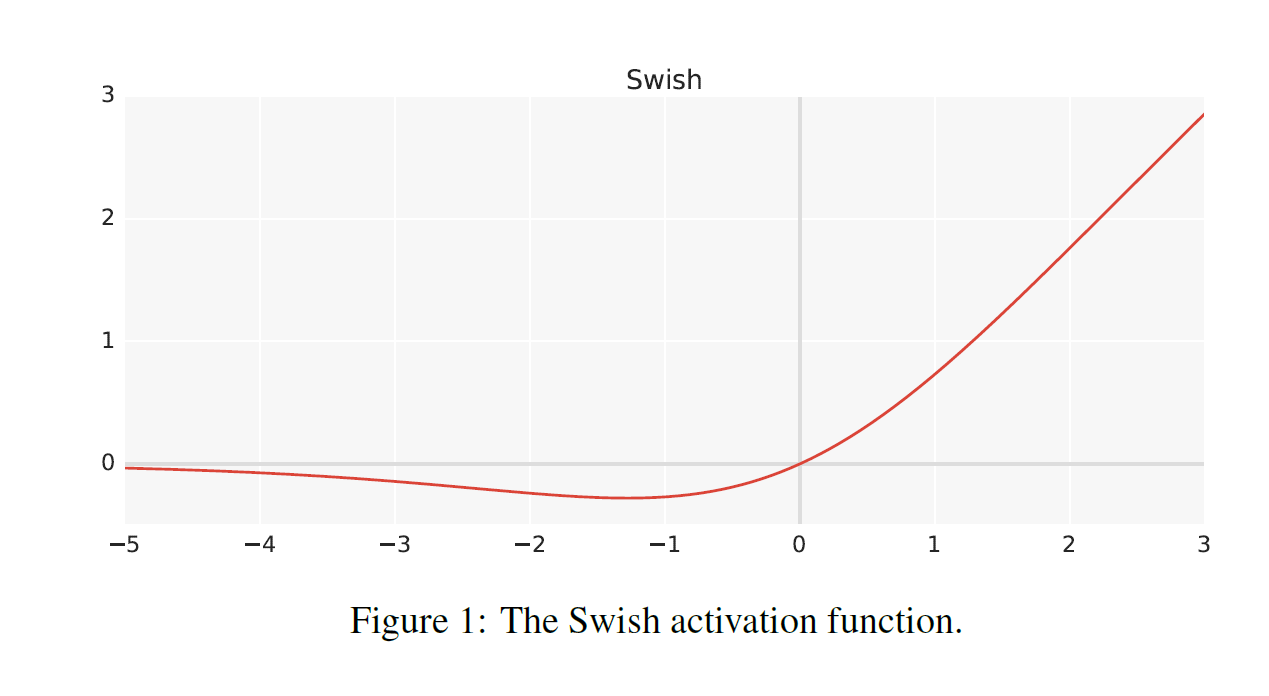
Feed Forward Module

Pre-norm 적용
Swish activation : regularizing에 도움
Conformer Block
Macaron-Net에 영감을 받아서 2개의 FFN에 쌓인 Sandwich 구조로 구성.
FFN 모듈에 half-step residual connection 적용

뒤의 Ablation study에서 Macaron-net FFN과 half-step residual connection이 성능 향상에 많은 기여를 했다고 함
Experiment
Data
- LibriSpeech
- 80 channel filterbank, 25ms window, 10ms stride
- SpecAugment (F=27), ten time masks (maximum ratio 0.05)
Conformer Transducer
- Three models: 10M, 30M, and 118M params
- Decoder: single LSTM-layer (Transducer)
- Dropout ratio: 0.1
- Adam optimizer, β1=0.9, β2=0.98 and έ=10^-9
- Learning rate scheduler: transformer lr scheduler, 10k warm-up steps
- 3-layer LSTM language model (LM) with 4096 hidden dimension (shallow fusion)
Results on LibriSpeech


- Conformer Block vs Transformer Block (without external LM)





Conclusion
Transformer + CNN 구조인 Conformer를 제안했고, 이를 잘 결합하기 위한 다양한 실험을 해서 결과를 냄.
Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox