Sooftware NLP - RoBERTa Paper Review
RoBERTa
Abstract
- BERT를 제대로 학습시키는 법을 제안
- BERT는 엄청난 모델이지만, Original BERT 논문에서 하이퍼파라미터에 대한 실험이 제대로 진행되지 않음
- BERT를 더 좋은 성능을 내게 하기 위한 replication study.
Background (BERT)
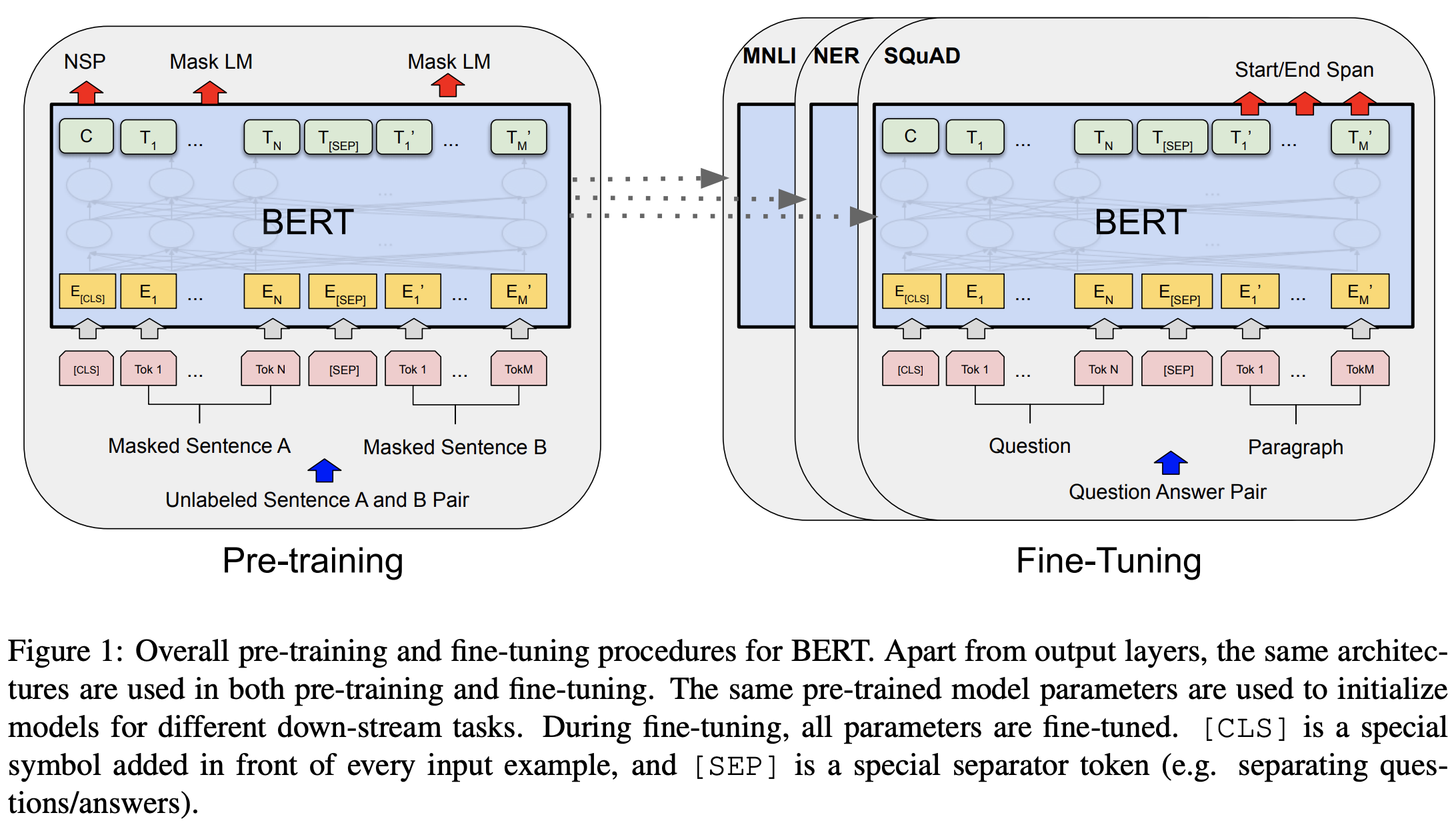
- 학습 1단계) 많은 양의 unlabeled corpus를 이용한 pre-train
- 학습 2단계) 특정 도메인의 태스크에 집중하여 학습하는 fine-tuning
- “Attention Is All You Need”에서 제안된 transformer의 encoder를 사용
Main Idea
Dynamic Masking
- 기존의 BERT는 학습 전에 데이터에 무작위로 mask를 씌움.
- 매 학습 단계에서 똑같은 mask를 보게 됨. (static masking)
- 이를 같은 문장을 10번 복사한 뒤 서로 다른 마스크를 씌움으로써 해결하려고 했지만, 이는 크기가 큰 데이터에 대해서 비효율적임.
- RoBERTa는 매 에폭마다 mask를 새로 씌우는 dynamic masking을 사용
- 결과: static masking보다 좋은 성능을 보여줌
Input Format / Next Sentence Prediction
- 기존 BERT에서는 Next Sentence Prediction(NSP)이라는 과정이 있었음
-
- 두 개의 문장을 이어 붙인다
-
- 두 문장이 문맥상으로 연결된 문장인지를 분류하는 binary classification을 수행
-
- RoBERTa는 NSP에 의문을 제기하고, Masked Language Modeling (MLM)만으로 pre-training을 수행
- NSP를 없앰으로써 두 문장을 이어 붙인 형태의 인풋 형태를 사용할 필요가 없어졌고, RoBERTa는 최대 토큰 수를 넘어가지 않는 선에서 문장을 최대한 이어 붙여서 input을 만들 수 있었음
[CLS]가나다라마바사아자카타파하[SEP]오늘 날씨가 좋은걸?[SEP]튜닙은 정말 대단한 회사야!.....[SEP]오늘은 빨리 퇴근하고 싶다.- BERT는 짧은 인풋들을 이어붙이는 경우도 있었지만, RoBERTa는 모든 인풋 토큰 수를 최대길이에 가깝게 사용할 수 있었음 (학습 효율면에서 좋음)
- 결과: NSP를 없앤 BERT가 기존의 BERT보다 더 나은 성능을 보임.
Batch Size
- (batch size X step 수)가 일정하게 유지되는 선에서 배치사이즈에 따른 성능 실험
- batch size가 256에 step이 1M이라면 batch size가 2K에 step이 125K가 되도록. (둘의 곱이 같도록 유지)
- 배치가 클수록 성능이 좋아지는 경향을 보임.
Data
- 데이터가 많을수록 BERT의 성능이 좋아지는 경향을 이전 연구들에서 관찰됐었음.
- 기존 BERT는 16GB로 학습했는데, RoBERT는 160GB의 데이터로 학습하였음.
- 당연하게도 160GB로 학습한 RoBERTa가 더 좋은 성능을 기록함
- 학습 시간을 길게 하면 할수록 더 좋은 성능을 보였다고함.
Conclusion
- 160GB의 데이터
- Dynamic Masking
- NSP 밴
- 최대한 문장을 구겨넣은 인풋 ([SEP]으로 분리)
- 큰 배치사이즈
Subscribe to SOOFTWARE
Get the latest posts delivered right to your inbox